Go And Unicode I Was Born To Love You
<<I was born to love you>> is a famous song from Queen, this can be used to describe the relationship between go(lang) and utf-8 encoding. Because source code in golang is encoded with utf-8, so is the string literals. Go also have a unicode/utf-8 package to deal with utf-8 processing. Now let’s talk about what is UTF-8 and how go(lang) deal with it.
1. UTF-8
As a programmer, the first and foremost encoding method you know is ACSII(US). It’s simple and compact, which encode a small set of characters(invisibles and visibles). But as you can see, life is much more complicated than what we think, the world is full of different characters. As an example, when you read english articals, you just need remember the 24 characters in the alphabet. If you are born to be a chinese man, you will have to remember thousand of characters before you can read a artical. [That’s why chinese is so horrible to learn :)]
If one byte can’t encode all this characters in our world. Then the unicode come to rescure. UTF-8 is a varible-length encoding of Unicode code points as bytes. The following is the encoding rule of utf-8:

- A high-order 0 indicates 7-bit ASCII
- A high-order 110 indicates the character take 2 bytes
- A high-order 1110 indicates the character take 3 bytes
- A high-order 11110 indicates the character take 4 bytes
2. Golang process UTF-8 string
First, let’s inspect a chinese version hello-world:
package main
import (
"fmt"
"unicode/utf8"
)
func main() {
s := "hello, 世界"
fmt.Println(len(s))
fmt.Println(utf8.RuneCountInString(s))
}
the len(s) calculate the byte length of the string, which is 13;
13 = 5("hello") + 2(, and a space) + 6("世界")
the utf8.RuneCountInString(s) calculate the character length of the string, which is 9, we just can find 9 “characters” use our naked eyes.
Now, let’s use another program to check each character:
package main
import (
"fmt"
"strconv"
"strings"
"unicode/utf8"
)
func main() {
s := "hello, 世界"
for i := 0; i < len(s); {
biVersion := strconv.FormatInt(int64(s[i]), 2)
if len(biVersion) < 8 {
fmt.Printf("[ascii: %s]\n", biVersion)
i++
} else if strings.HasPrefix(biVersion, "110") {
r, _ := utf8.DecodeRuneInString(string(s[i:]))
fmt.Printf("[values < 128 unused: %s, %c]\n", biVersion, r)
i += 2
} else if strings.HasPrefix(biVersion, "1110") {
r, size := utf8.DecodeRuneInString(string(s[i:]))
fmt.Printf("[values < 2048 unused: %s, %c, size: %d]\n", biVersion, r, size)
i += 3
} else if strings.HasPrefix(biVersion, "11110") {
r, _ := utf8.DecodeRuneInString(string(s[i:]))
fmt.Printf("[other value used: %s, %c]\n", biVersion, r)
i += 4
}
}
}
this is the runnig result:
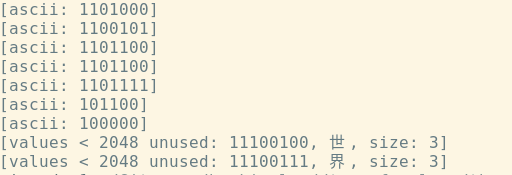
Yes! The unicode of ‘世’ start with “1110” in the string, and the byte-length is 3.
Golang and UTF-8! Do you get it? Bye! :)